Kubernetes v1.33 cuts API memory usage by 95%
Kubernetes v1.33 just solved one of the biggest headaches in large-scale cluster operations: memory bloat from List requests.
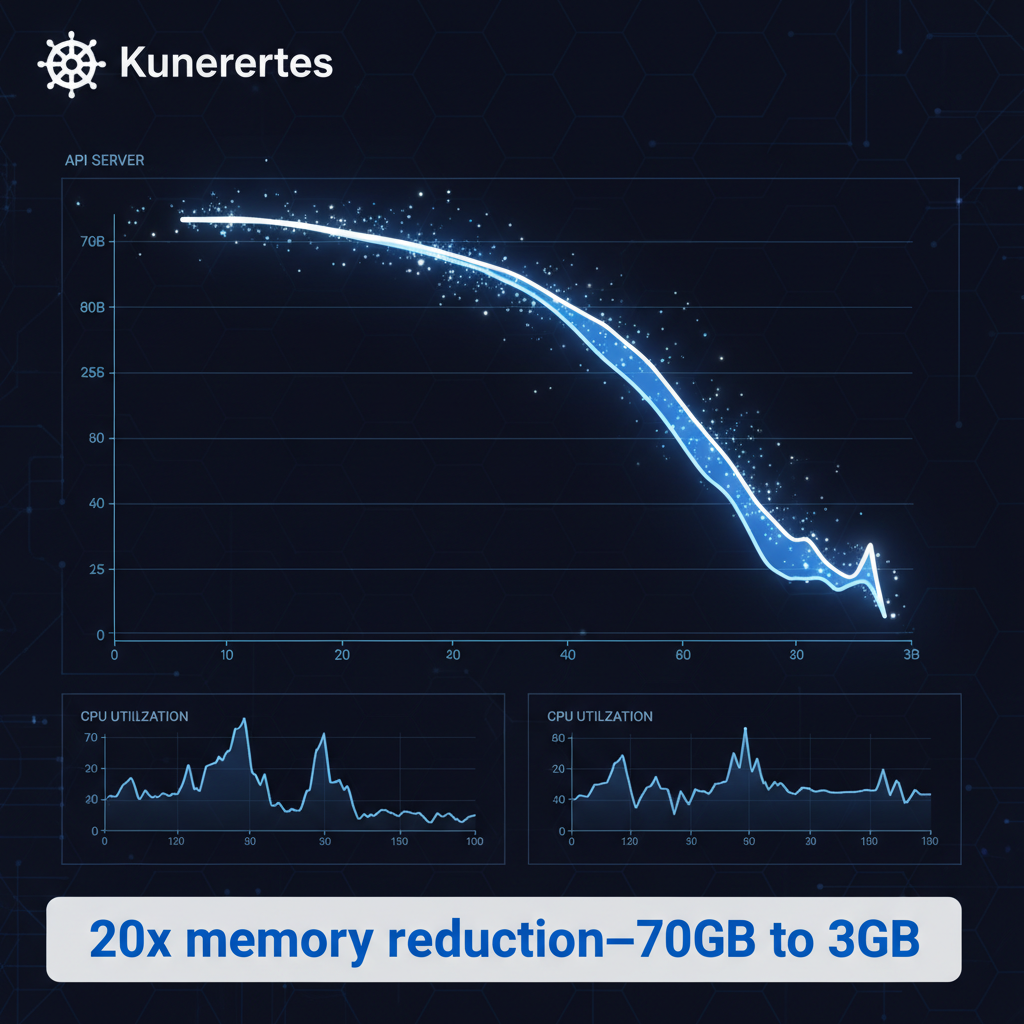
Here's what happened. Your kube-apiserver was holding entire API responses in memory as single blocks—sometimes hundreds of megabytes. Even with HTTP/2 splitting responses into frames, the server couldn't free that memory incrementally. When network congestion hit, those massive buffers stayed active for minutes. Multiple concurrent List requests? OOM kills waiting to happen.
The fix is streaming encoding. Instead of serializing everything at once, the API server now processes each item individually and transmits it. Memory gets freed as you go. Predictable. Manageable. Stable.
The numbers are wild: 10 concurrent requests returning 1GB each used to consume 70-80GB of memory. Now? 3GB. That's a 20x improvement.
And here's the kicker—it's completely backward compatible. Your clients don't change. Your manifests don't change. The encoding just gets smarter under the hood.
If you're running large clusters with heavy API traffic, this is the kind of architectural win that prevents 3am incidents.