Amazon Bedrock Managed Knowledge Base launches
Most teams building knowledge bases for AI agents spend weeks connecting data sources, tuning chunking strategies, and debugging retrieval accuracy. Amazon Bedrock Managed Knowledge Base removes that overhead entirely by managing the full RAG pipeline as a single primitive.
The service abstracts storage, retrieval, embeddings, re-ranking, and model selection into one managed component. Developers point at their data sources and start querying. No manual assembly of infrastructure pieces. No experimentation cycles to find the right parsing approach. The system selects defaults automatically, then lets teams customize when needed.
Three features stand out. Smart Parsing determines the optimal strategy for each data type and connector without configuration. The Web Crawler connector preserves HTML structure and embedded images. SharePoint connectors maintain document hierarchy. Multimodal processing detects content types within documents and sends them to foundation models for extraction and captioning.
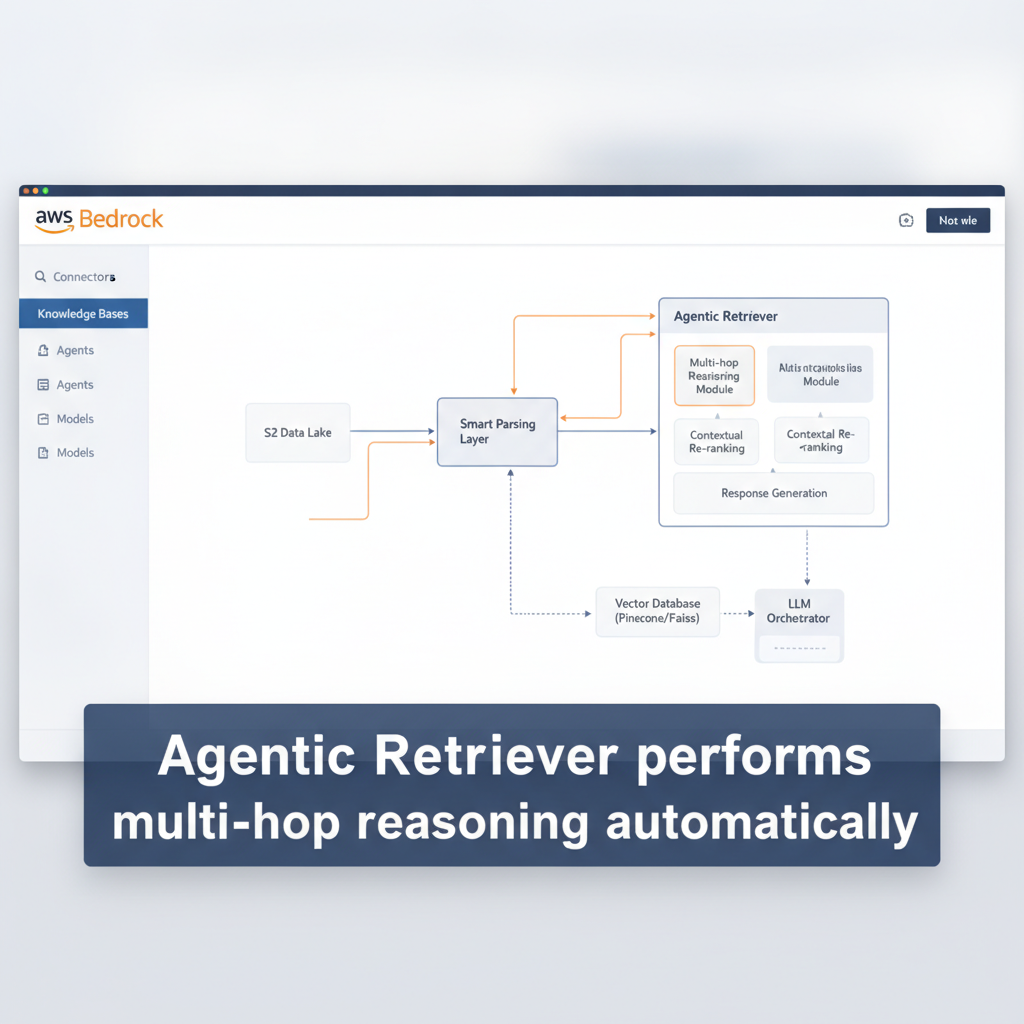
Agentic Retriever handles queries that require multi-step reasoning. A user asking about cloud infrastructure budgets and expense policies triggers a step-by-step query plan. The system identifies which team owns the ML platform, retrieves their budget, checks the expense policy on annual commitments, then determines whether the policy allows prepayment against that budget. Each step performs retrieval and reasoning before moving forward.
This multi-hop approach stops when sufficient context is gathered. Single-step retrieval often surfaces relevant documents but fails to connect information spread across sources. Breaking queries into logical steps and reasoning at each stage improves accuracy for complex questions without requiring developers to build separate orchestration logic.
Six native connectors at launch
Managed Knowledge Base ships with connectors for Amazon S3, SharePoint, Confluence, Web Crawler, Google Drive, and OneDrive. Each connector handles application-specific requirements automatically. IAM roles are created during setup, with the option to edit permissions if needed.
Integration with AgentCore Gateway adds Knowledge Base as a native target type alongside MCP servers, Lambda functions, and REST APIs. Selecting a knowledge base ID exposes it through the gateway. No manual integration code required. The gateway exposes the Model Context Protocol, so knowledge base tools are automatically discovered by MCP-compatible frameworks including LangChain, CrewAI, LlamaIndex, and LangGraph.
Model flexibility remains intact. Every foundation model available on Bedrock can power generation. Developers select embedding and re-ranking models to optimize retrieval for their use case. The service separates infrastructure management from model selection, so teams can adopt new models as they become available without rebuilding pipelines.
Managed Knowledge Base uses the same APIs as existing Bedrock Knowledge Bases: Retrieve, StartIngest, StopIngest, and IngestKnowledgeBaseDocuments. Migration requires changing the knowledge base ID. No code changes needed.
Pricing and availability
The service is available in US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London), and AWS GovCloud (US-West). Pricing is based on indexed data stored and retrievals performed. No upfront commitments. AWS Free Tier applies for new customers.
Smart Parsing eliminates weeks of experimentation typically required to reach production-quality retrieval accuracy. Different document types need different chunking strategies. Foundation models analyze document structure and extract meaningful content. Intelligent defaults balance accuracy with performance based on content type, while advanced users can customize when necessary.
Agentic Retriever can be tested directly from the knowledge base test panel in the AgentCore console. Select "Agentic retrieval only" as the retrieval type to let the system plan and execute multi-step queries automatically. Maximum agentic iterations can be configured to control how many reasoning steps are allowed.
The service addresses three problems developers face when building knowledge bases. Connecting to enterprise data requires custom connectors for each source, each with different content types and access controls. Optimizing RAG accuracy demands experimentation with parsing strategies, chunking approaches, and embedding models. Managing infrastructure at scale means serving millions of documents or thousands of smaller knowledge bases reliably.
These tasks are undifferentiated work. Teams spend time on infrastructure instead of applications. Managed Knowledge Base consolidates these components into a single managed primitive, so developers focus on business outcomes rather than pipeline maintenance.
AgentCore Gateway integration provides built-in observability, policy enforcement, and automatic permission management. The AgentCore Observability dashboard surfaces evaluation metrics for knowledge base performance. Role-based permissions are auto-generated, reducing integration to a few lines of code.
The separation of infrastructure from model choice matters for long-term flexibility. Managed solutions that lock teams into specific model providers create friction when requirements change. Bedrock Managed Knowledge Base lets teams switch between smaller models for simple queries and more capable models for complex reasoning without changing infrastructure.
Connector-specific data models optimize handling for each source. The Web Crawler preserves rich content that might otherwise be dropped during ingestion. SharePoint connectors maintain relationships between files. These optimizations happen automatically based on the connector type selected during setup.
Multimodal processing identifies bounding boxes in documents and sends them to foundation models for data extraction. Video files receive captioning and scene descriptions. This ensures complex documents with mixed formats are properly indexed without manual preprocessing.
Organizations building agentic AI applications need secure, reliable, and current access to enterprise data. Managed Knowledge Base provides that access while removing the complexity of building and maintaining RAG pipelines. The result is faster development cycles and more accurate retrieval without sacrificing flexibility.